"Cuidado com os idos de março". Sim, é finalmente essa época do ano: quando os imperadores do basquete universitário devem ficar de olho nas costas, para que as sementes inferiores do torneio não venham.
Antes de 15 de março, milhões de pessoas em todo o mundo preencherão seus colchetes da March Madness. Em 2017, a ESPN recebeu um recorde de 18, 8 milhões de chaves.
O primeiro passo para um suporte perfeito é escolher corretamente o primeiro turno. Infelizmente, a maioria de nós não pode prever o futuro. No ano passado, apenas 164 dos braquetes apresentados foram perfeitos durante o primeiro turno - menos de 0, 001 por cento.
18, 8 milhões de braquetes submetidos.
- ESPN Fantasy Sports (@ESPNFantasy) 18 de março de 2017
164 são perfeitos após o Round 1.
Está aqui para overachieving. #perfectbracketwatch pic.twitter.com/TGwZNCzSnW
Muitos parênteses são eliminados quando uma equipe com menor número de unidades prejudica a maior semente preferida. Desde que o campo expandiu para 64 equipes em 1985, pelo menos oito transtornos ocorrem em média a cada ano. Se você quiser ganhar seu pool de suporte, é melhor você escolher pelo menos algumas surpresas.
Somos dois Ph.D. em matemática. candidatos na Ohio State University, que têm uma paixão pela ciência de dados e basquete. Este ano, decidimos que seria divertido construir um programa de computador que usa uma abordagem matemática para prever problemas de primeira rodada. Se estivermos certos, um suporte escolhido usando nosso programa deve ter um desempenho melhor na primeira rodada do que o suporte médio.
Humanos falíveis
Não é fácil identificar qual dos jogos da primeira rodada resultará em uma virada.
Digamos que você tenha que decidir entre a semente No. 10 e a semente No. 7. O n º 10 sementes tem arrancado em suas últimas três aparições no torneio, uma vez até mesmo fazendo o Final Four. A semente número 7 é uma equipe que recebeu pouca ou nenhuma cobertura nacional; o fã casual provavelmente nunca ouviu falar deles. Qual você escolheria?
Se você escolhesse a semente número 10 em 2017, você teria ido com a Virginia Commonwealth University em Saint Mary's da Califórnia - e você estaria errado. Graças a uma falácia de tomada de decisão chamada viés de recência, os seres humanos podem ser induzidos a usar suas observações mais recentes para tomar uma decisão.
O viés de recência é apenas um tipo de viés que pode se infiltrar no processo de seleção de alguém, mas há muitos outros. Talvez você seja inclinado para o seu time da casa, ou talvez você se identifique com um jogador e queira desesperadamente que ele ou ela seja bem-sucedido. Tudo isso influencia sua faixa de maneira potencialmente negativa. Mesmo profissionais experientes caem nessas armadilhas.
Problemas de modelagem
O aprendizado de máquina pode se defender contra essas armadilhas.
No aprendizado de máquina, estatísticos, matemáticos e cientistas da computação treinam uma máquina para fazer predições, permitindo que ela “aprenda” a partir de dados passados. Essa abordagem tem sido usada em diversos campos, incluindo marketing, medicina e esportes.
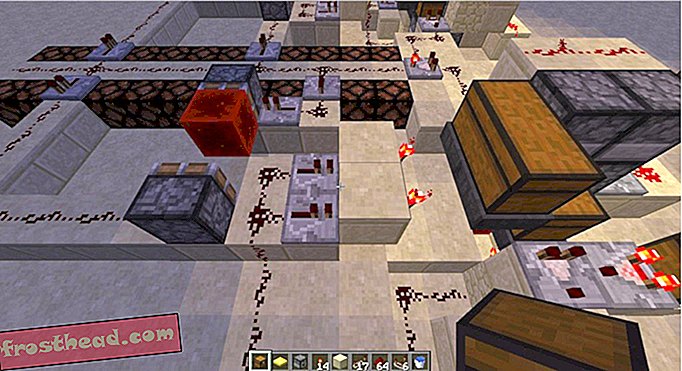
Técnicas de aprendizado de máquina podem ser comparadas a uma caixa preta. Primeiro, você alimenta os dados passados do algoritmo, essencialmente configurando os mostradores na caixa preta. Depois que as configurações são calibradas, o algoritmo pode ler novos dados, compará-los a dados passados e depois citar suas previsões.
 Uma visualização em caixa preta de algoritmos de aprendizado de máquina. (Matthew Osborne, CC BY-SA)
Uma visualização em caixa preta de algoritmos de aprendizado de máquina. (Matthew Osborne, CC BY-SA) No aprendizado de máquina, há uma variedade de caixas pretas disponíveis. Para o nosso projeto March Madness, os que queríamos são conhecidos como algoritmos de classificação. Isso nos ajuda a determinar se um jogo deve ou não ser classificado como um transtorno, seja fornecendo a probabilidade de um transtorno ou classificando explicitamente um jogo como um.
Nosso programa usa vários algoritmos de classificação populares, incluindo regressão logística, modelos florestais aleatórios e vizinhos com k mais próximos. Cada método é como uma “marca” diferente da mesma máquina; eles funcionam de maneira diferente sob o capô como Fords e Toyotas, mas realizam o mesmo trabalho de classificação. Cada algoritmo, ou caixa, tem suas próprias previsões sobre a probabilidade de uma virada.
Usamos as estatísticas de todas as equipes da primeira rodada de 2001 a 2017 para definir os mostradores em nossas caixas pretas. Quando testamos um de nossos algoritmos com os dados da primeira rodada de 2017, ele apresentava uma taxa de sucesso de cerca de 75%. Isso nos dá a confiança de que a análise de dados passados, em vez de apenas confiar em nosso intestino, pode levar a previsões mais precisas de transtornos e, portanto, melhores parênteses gerais.
Que vantagens essas caixas têm sobre a intuição humana? Por um lado, as máquinas podem identificar padrões em todos os dados de 2001-2017 em questão de segundos. Além disso, como as máquinas dependem apenas de dados, elas podem ter menor probabilidade de cair em preconceitos psicológicos humanos.
Isso não quer dizer que o aprendizado de máquina nos dará suportes perfeitos. Mesmo que a caixa ignore o preconceito humano, não é imune a erros. Os resultados dependem de dados passados. Por exemplo, se uma semente No. 1 perdesse na primeira rodada, nosso modelo provavelmente não a anteciparia, porque isso nunca aconteceu antes.
Além disso, os algoritmos de aprendizado de máquina funcionam melhor com milhares ou até milhões de exemplos. Apenas 544 jogos de March Madness da primeira rodada foram jogados desde 2001, então nossos algoritmos não irão chamar corretamente todos os problemas. Especialista em basquete de eco, Jalen Rose, nossa saída deve ser usada como uma ferramenta em conjunto com seu conhecimento especializado - e sorte! - para escolher os jogos corretos.
Loucura de aprendizado de máquina?
Não somos as primeiras pessoas a aplicar o aprendizado de máquina ao March Madness e não seremos os últimos. Na verdade, as técnicas de aprendizado de máquina podem em breve ser necessárias para tornar sua chave competitiva.
Você não precisa de um diploma em matemática para usar aprendizado de máquina - embora isso nos ajude. Em breve, o aprendizado de máquina pode estar mais acessível do que nunca. Os interessados podem dar uma olhada em nossos modelos online. Sinta-se à vontade para explorar nossos algoritmos e até mesmo criar uma abordagem melhor.
Este artigo foi originalmente publicado no The Conversation.
Matthew Osborne, Ph.D Candidato em Matemática, The Ohio State University
Kevin Nowland, Ph.D Candidato em Matemática, The Ohio State University